 OA系统
OA系统
 炸金花
邮箱
炸金花
邮箱
 教务管理
教务管理
 资源下载
资源下载
 English
English


炸金花


炸金花 李挥教授实验室在软件工程与大模型代码安全领域取得系列进展
 发布时间:2026-05-09
发布时间:2026-05-09
 浏览次数:
浏览次数:
近日,国家重大科技基础设施—未来网络北大实验室在软件工程与大模型代码安全方向取得系列重要成果。由实验室李挥老师指导、王滨博士生参与完成的两篇研究论文同时被软件工程领域顶级国际会议ICSE 2026(IEEE/ACM International Conference on Software Engineering)录用,分别为《Argus: A Multi-Agent Sensitive Information Leakage Detection Framework Based on Hierarchical Reference Relationships》和《Attention Distance: A Novel Metric for Directed Fuzzing with Large Language Models》。
ICSE 是国际软件工程领域公认的顶级学术会议之一,长期被视为该领域最具影响力的旗舰会议。会议汇聚全球高校、研究机构与头部科技企业的前沿研究成果,对论文的创新性、严谨性和实际价值均有极高要求。两篇论文同时入选 ICSE,充分体现了实验室在软件工程智能化、安全分析与大模型赋能软件工程等方向上的持续创新能力和国际学术竞争力。

图1IEEE/ACM International Conference on Software Engineering官网主页节选

图2团队成员在会场进行现场报告
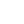
其中,论文《Argus: A Multi-Agent Sensitive Information Leakage Detection Framework Based on Hierarchical Reference Relationships》聚焦开源代码仓库中的敏感信息泄露检测难题。针对传统基于正则规则、指纹特征和信息熵的检测方法误报率高、人工筛查成本大的问题,研究团队提出了多智能体协同检测框架 Argus。该方法从敏感信息内容本身、文件级上下文语义以及项目级引用关系三个层次开展联合分析,通过多智能体分工协作,有效提升了真实泄露识别能力,并显著降低伪阳性比例。论文还构建了两个面向真实仓库场景的新基准数据集,用于分别评估泄露检测能力和误报过滤能力。实验结果展现出较强的工程实用性与落地能力。
图3 Argus框架图
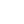
论文《Attention Distance: A Novel Metric for Directed Fuzzing with Large Language Models》面向软件安全测试中的定向灰盒模糊测试问题展开研究。现有定向模糊测试方法大多依赖程序结构上的“物理距离”来评估输入与目标漏洞位置的接近程度,但这类方法往往忽略代码路径之间真实的逻辑依赖,容易在复杂程序中产生路径误导,影响漏洞触发效率。针对这一瓶颈,研究团队提出了新的距离度量指标 Attention Distance,将大语言模型对代码语义关系的理解能力引入定向模糊测试,通过为代码语句分配上下文相关的注意力分数,形成更具判别力的路径引导信号。实验结果显示,在不改变 AFLGo 其他组件、仅替换距离度量方式的条件下,该方法在 38 个真实漏洞复现实验中带来了平均 3.43 倍的测试效率提升;相较于先进定向模糊测试工具 DAFL 和 WindRanger,分别实现了 2.89 倍和 7.13 倍的性能提升,验证了大模型语义分析能力赋能软件安全测试的广阔前景。
图4 Attention Distance框架图
此外,团队近两年还在AAAI(标准化agent模块增持agent代码生成框架进行安全代码生成)、ICML(强化学习提升代码安全能力)、ACL(repo级别代码安全生成)等AI领域顶会发表多篇LLM与代码安全相关论文,还有软工领域影响力刊物《Empirical Software Engineering》(缺陷的prompt对于代码安全生成的影响实证分析)。
除高水平论文成果外,实验室还围绕大模型代码安全与AI 系统安全持续推进开源平台建设,并与腾讯合作推出了两项具有代表性的成果。其一是 A.S.E(AICGSecEval),这是一个面向项目级 / 仓库级 AI 生成代码安全评测的基准与评估框架,旨在通过模拟真实软件开发流程,系统评估 AI 辅助编程场景下生成代码的安全性。公开资料显示,该框架重点关注真实工程语境下的代码安全评测,覆盖多种主流编程语言及多类常见安全风险类型,为 AI 生成代码安全研究提供了更贴近实际的软件仓库级评测基础。且A.S.E 发布后获得了广泛关注。在Hugging Face网站的“Paper of the Day” 排名第一,并登上 2025 年第 36 周周榜首位,体现出较强的趋势影响力和社区认可度。
图5huggingface榜单
另一项成果A.I.G(AI-Infra-Guard) 则面向 AI 生态安全构建了全栈 AI 红队测试平台。该平台集成 OpenClaw 安全检测、Agent Scan、MCP 扫描、AI 基础设施漏洞扫描、模型越狱评测等多种能力,覆盖从 Agent 工作流到底层基础设施的安全分析需求,体现了实验室在 AI 系统安全、工具链建设和复杂场景自动化安全评估方面的系统化探索。公开信息显示,A.I.G 已形成较完整的平台能力框架,为 AI 应用、智能体系统以及相关开发生态提供了较强的安全评估支撑。两项成果均在开源社区取得广泛影响力,均已经收获GitHub社区上千star。

图6 A.I.G项目Github项目主页节选
在理论总结与知识体系建设方面,实验室出版的学术著作《大语言模型与安全代码生成》以及英文版专著《Large Language Models and Secure Code Generation》立足大语言模型快速演进与AI 辅助编程广泛落地的时代背景,围绕代码生成的核心原理、安全增强方法、评测体系与未来发展趋势进行了系统梳理。从大语言模型的发展脉络与 Transformer 语义建模原理出发,逐步展开面向代码的大语言模型、LLM 安全增强相关技术、代码生成安全增强方法、代码生成模型的评估与实践,以及人工智能范式革新与网络空间安全内在融合等内容,形成了较为完整的知识框架,体现出实验室在大模型代码生成与安全增强方向上的长期积累和系统思考。

图7团队英文专著封面
未来,实验室将继续围绕大模型时代的软件工程基础理论、智能安全评测方法以及安全可信代码生成系统开展深入研究,不断推动相关成果在学术界与产业界的双向落地。